.jpeg)
Spark, Flink, Kafka Streaming ...
Streaming 101
ㅁ Latency & Throughput
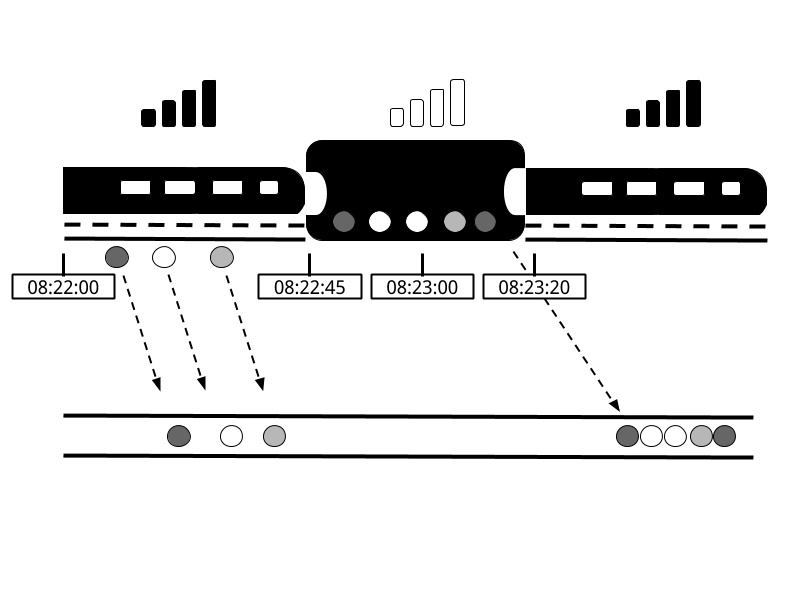
- Latency : Processing 완료 시간 - Event 발생 시간
보통 이와 같이 정의됩니다. 하지만 이렇게 정의할 경우 위 그림처럼 사용자가 인터넷이 되지 않는 터널등의 구간에서의 Event 발생 ( = 엔지니어들이 해결해 줄수 없는 영역으로 인한 Latency ) 등이 있기에 보통 Latency 는 Event 발생 시간 대신 Log Collector 역할을 하는 서버가 로그를 받은 시간으로 대신하는 경우가 많습니다.
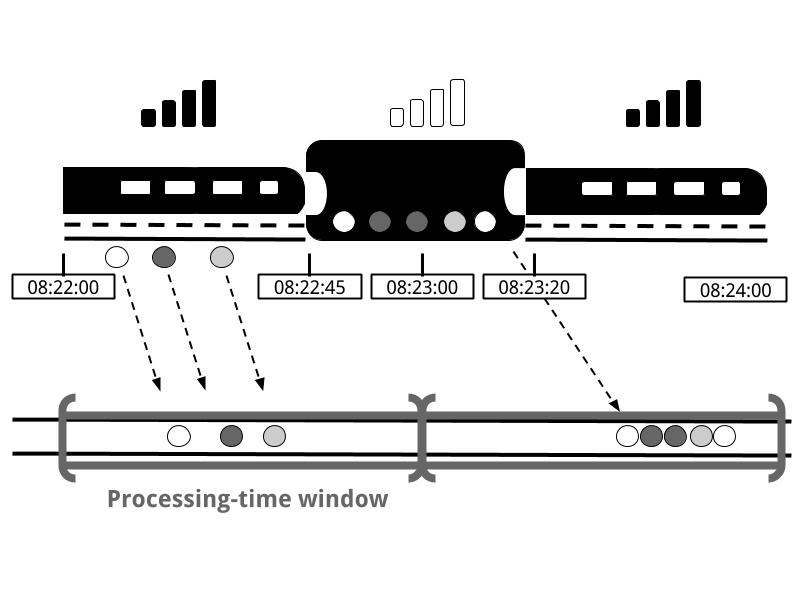
- Throughput : Streaming 서버의 시간당 처리량
메시지가 적을땐 Streaming Service 의 Throughput 이 시스템에 큰 영향을 주지 않습니다. 하지만 위처럼 유입되는 메시지가 많아지면 Streaming Service 의 Throughput 은 서비스의 품질을 결정짓는 중요한 요소가 됩니다. 서버가 시간당 처리하는 메시지 양이 적으면 처리 속도가 느려질테고, Latency 는 점점 증가하겠죠. 이럴땐 Scale out 을 하건 더 빠른 처리가 가능하도록 로직을 수정하는 등의 운영을 해줘야 합니다.
Latency 와 Throughput 은 보통 대략적으로 반비례 관계에 있다는 말을 합니다. Streaming 서비스의 Throughput 이 유입되는 Input 량보다 현저히 떨어지면 당연히 Latency 가 올라갈 것이고, Throughput 이 높으면 유입되는 Input 들을 빨리 빨리 처리할테니 Latency 는 줄어들 것입니다.
ㅁ SQL Streaming
- Spark’s Structured Streaming
- Flink’s Data Stream SQL
- Kafka’s kSQL
ㅁ 그 이외에 Streaming 에서 중요한 개념들!
- Exactly Once, At most once, At least once
- Time Windowed
- How to manage State! ( in Stateful Streaming )
- How to manage log
- How to Fail-over, Alert, Restart
- How to Scale out
- How to Monitoring Metric
결국 어려운건 운영입니다… Streaming 시스템에서 Latency & Throughput 도 매우 중요한 요소이지만 “어떻게 운영할 것인가? 운영포인트를 줄여갈 것인가?”도 매우매우 중요한 요소입니다. 이게 없으면 Streaming F/W 이라 할 수 없죠.
ㅁ 위에서 한 얘기들 실제 Streaming 시스템에서 어떻게 처리하는지가 궁금하시다면! :)
링크 : Spark Streaming 운영 및 회고
오늘 얘기에서는 위에 내용들을 어떻게 처리하고 관리하는지를 보기 위함은 아니라 패스 하겠습니다!
나중에 기회가 되면 Spark Streaming 운영과 회고 발표 슬라이드도 글로 옮겨야 겠네요 ^^;
Streaming Service
- 오늘은 Kafka, Spark, Flink :) 이 3개의 서비스를 한번 비교해볼까 합니다.
Kafka streaming
Kafka 0.9 부터 Kafka Streaming Client 를 지원합니다.
현재는 1.0 버전을 드디어! 런칭하면서 그 발전속도가 세상을 깜짝 놀라게 합니다.
Streaming 이 나온지 얼마 되지 않아 ksql 이라는 어마 무시한 kafka sql streaming 오픈소스가 나옵니다.
(링크 : ksql Github Repository )
최근에는 LINE Corperation 에서 상용서비스에 Kafka Streams 를 적용했고, 덕분에 Kafka 개발자들은 신이납니다.
( 보통 상용에 대한 검증을 큰 회사에서 한번 해주면 믿고 가면 되거든요 ㅋㅋ )
(링크 : 내부 데이터 파이프라인에 Kafka Streams 적용하기 )
ㅁ Resource Manager
카프카 스트림즈는 yarn 이나 mesus 같은 리소스 매니저를 통해 띄우지 않습니다.
( 물론 apache slider 나 다른 방법을 통해 띄우는 것들은 제외 하겠습니다. 기본 docs 에 없음을 말할 뿐 입니다)
그게 꼭 나쁜걸까요? Yarn 이나 Mesus 나 Network Resource Managing 은 하지 못합니다.
누군가 큰 쿼리를 돌리면 Streaming 서비스가 정상적으로 돌지 않는 ( 클러스터 전체가 정상적으로 돌지 않는 )
상태가 발생하기도 합니다
Streaming 서비스 같은 Long Running Service 들은 Stand Alone 형태로 띄울때가 ( = 네트워크 사용이나 리소스 사용이
예측이 안되는 클러스터와는 별도의 존에서 ) 나을 수도 있다는 생각이 듭니다.
ㅁ Client’s Service Discovery

이 책을 인용하자면 “인프라에서 동작중인 애플리케이션과 서비스는 종종 다른 애플리케이션이나 서비스를 찾는 방법을 알아야한다”
동일 토픽의 동일 group id 로 컨슘하고 있는 서버를 찾는 방법이 명령어 한줄에 뽝! 되는 그런 클린한 방법이 없습니다.
즉, 관리하던사람이 아닌 잘 모르는 사람, 인수인계 받아야 하는 사람이 오면 문서 없이는 꽤 고생하겠죠
ㅁ Monitoring
Kafka Streams Client 에 대한 모니터링이 존재하지 않습니다. ( = 별도로 붙여야 합니다. )
요샌 APM 이 쩌는게 워낙 많아서리… ㅎㅎ
VM 이나 Application 에 대한 모니터링이 워낙 잘 되어 있어 그런 부분의 솔루션이 회사에 존재한다면
이부분도 해결은 가능합니다 :)
Kafka Cluster 의 상태를 살펴 볼수 있는 Cruise Control for Apache Kafka 과 함께 쓰면 더 좋을것 같기도 하네요 :)
( 링크 : open-sourcing-kafka-cruise-control )
ㅁ Streaming SQL Engine
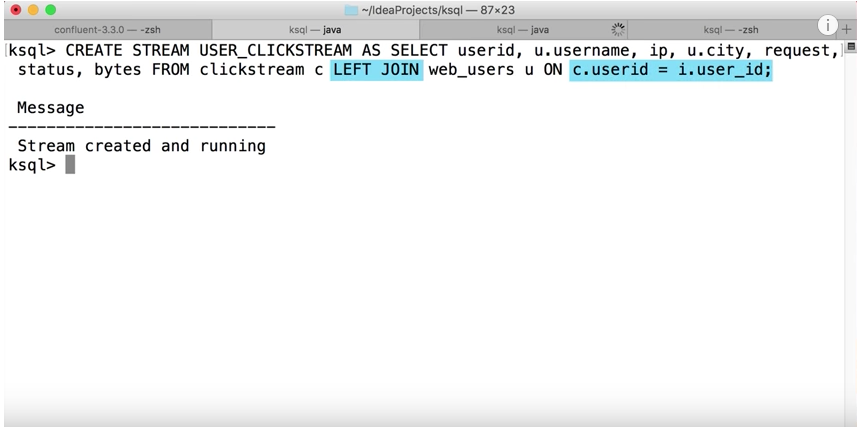
 Data Streaming 을 SQL 을 이용해서 Table 처럼 정의하고 Window 크기 만큼
빼서 사용이 가능하도록 만든 Kafka 만의 SQL Engine 입니다.
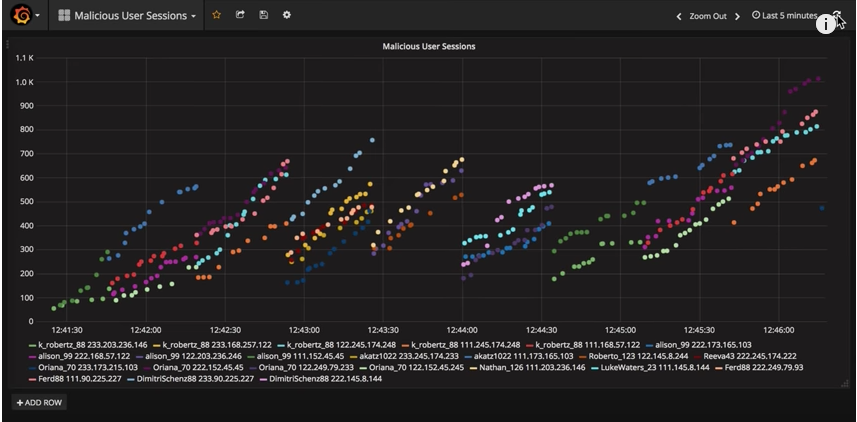
InfluxDB + Grafana 를 사용해서 Visualization 쉽게 가능하도록 되어 있네요!
자세한 설명은 아래 링크에서 튜토리얼 영상을 보세요 :)
Data Streaming 을 SQL 을 이용해서 Table 처럼 정의하고 Window 크기 만큼
빼서 사용이 가능하도록 만든 Kafka 만의 SQL Engine 입니다.
InfluxDB + Grafana 를 사용해서 Visualization 쉽게 가능하도록 되어 있네요!
자세한 설명은 아래 링크에서 튜토리얼 영상을 보세요 :)
( 링크 : KSQL github repository )
Spark Streaming
ㅁ This is not native streaming. Just “Micro Batch”
스팍 스트리밍은 스트리밍이 아니죠. 마이크로 배치 입니다.
event loop 가 돌며 batch job 을 계속 submit 하는 식으로 구현되어져 있습니다.
그래서 느리죠. 느려요. 느립니다

근데 서비스하면서 많이 느끼는게 정말 님들의 서비스는
“1초도 못 기다림.”
“2초도 못 기다림.”
“3초도 못 기다림.”
수 초도 지연되면 안되는 서비스 인가요? 물론 그런 서비스이실수도 있고,
아닐수도 있습니다. 수초도 지연되선 안된다면 Spark Streaming 은 절대 쓰시면 안됩니다.
단 그 부분만 Okay 된다면 Spark Streaming 만큼 괜찮은 서비스가 없습니다.
그 이유는 Micro Batch 특성 때문인데요. Native Streaming 과 Micro Batch 를 둘다 코딩해보신 분들은
왜 Micro Batch 가 좋은지 느낄 수도 있을것 같아요 ( 아! 물론 개인차가 있을순 있습니다 ㅎㅎ )
이렇게 Micro Batch 로 나눠져 있다는게 코딩할때 생각보다 생각을 덜 하게 해줍니다. :)
ㅁ Spark UI
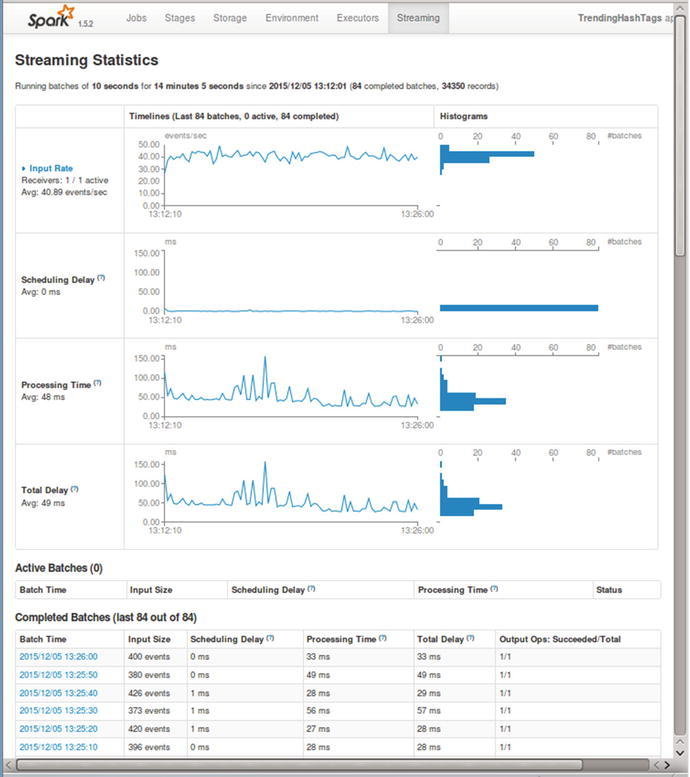
거의… 이거때문에 Spark 쓴다고 해도 과언이 아닐 정도로 잘 되어 있습니다.
이거 없이 Spark 운영한다고 하는 사람은 Spark 운영을 하지 않은 사람일 것입니다.
근데 이 부분 때문에 많은 오해가 생기기도 하더라구요.
그 예로 하나가 Delay Time 입니다.
Dealy Time 과 Streaming Latency 는 같은 값일까요? 또는 서로 비슷한 추세라도 보일까요?
답은 아닙니다.
Streaming Latency 는 보통( 살짝 다르게 쓰기도 하지만 )
Streaming Latency = 메시지(로그)의 Processing 처리 완료 시간 - Event 발생 시간
입니다.
Spark UI 에 나오는 Delay Time 은
Delay Time = Real Processing Time(실제 배치를 프로세싱 하는데 걸린 시간 ) - Micro Batch’s duration
입니다. :)
잘 만들어진 UI 는 편하긴 하지만 그 의미를 잘 모르면 오해를 불러일으키기 쉽습니다.
Flink
 Streaming에 이상할 만큼 특화된(=잘만들어진) F/W Flink 입니다.
Streaming에 이상할 만큼 특화된(=잘만들어진) F/W Flink 입니다.
Flink… 정말 Streaming 분야에서는 짱입니다..
그리고 로고가 동물인게 마음에 듭니다. 역사적으로 로고가 동물인게 잘 되더라구요.
Docker, Go, Linux 다 동물입니다 :)

아래에서 Flink 특징들 보면서 기능상 장단점을 한번 볼게요. :)
ㅁ Flink Dashboard
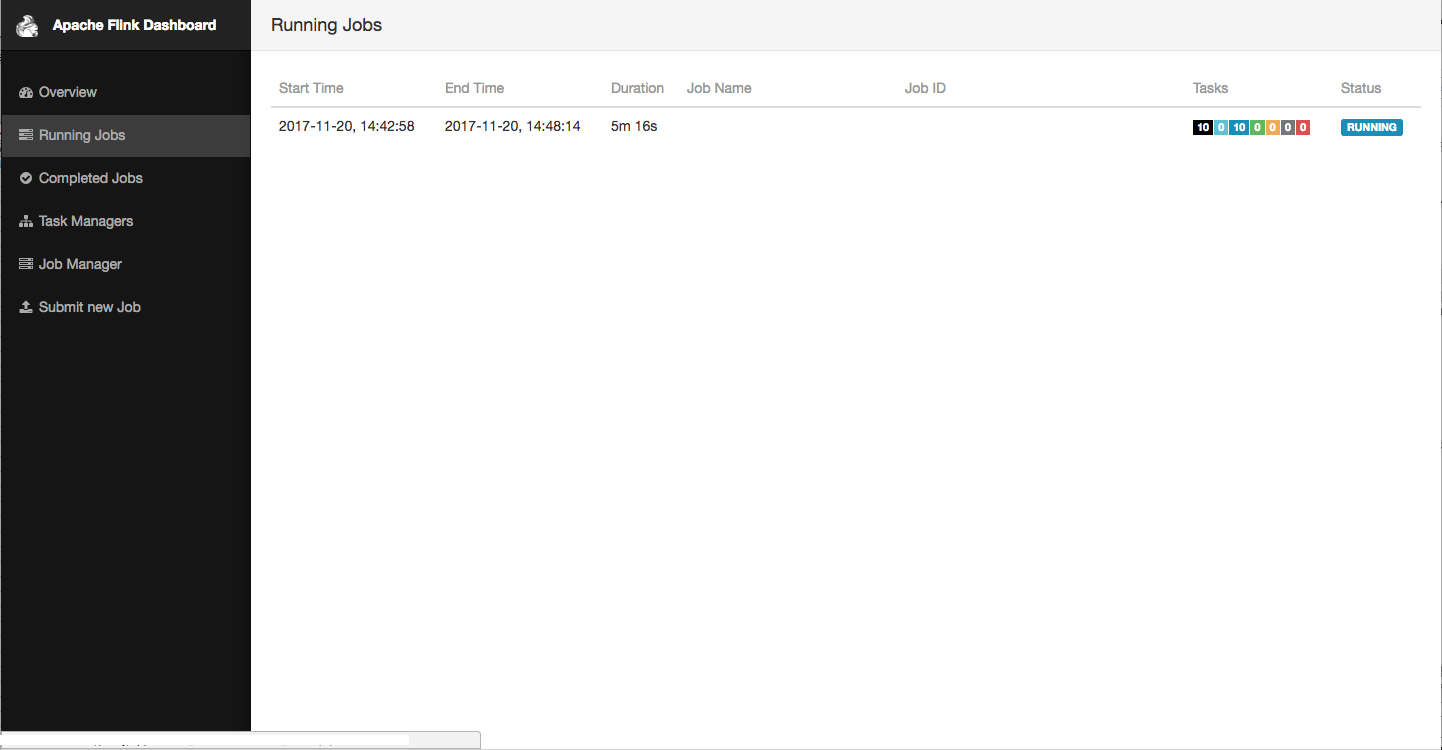
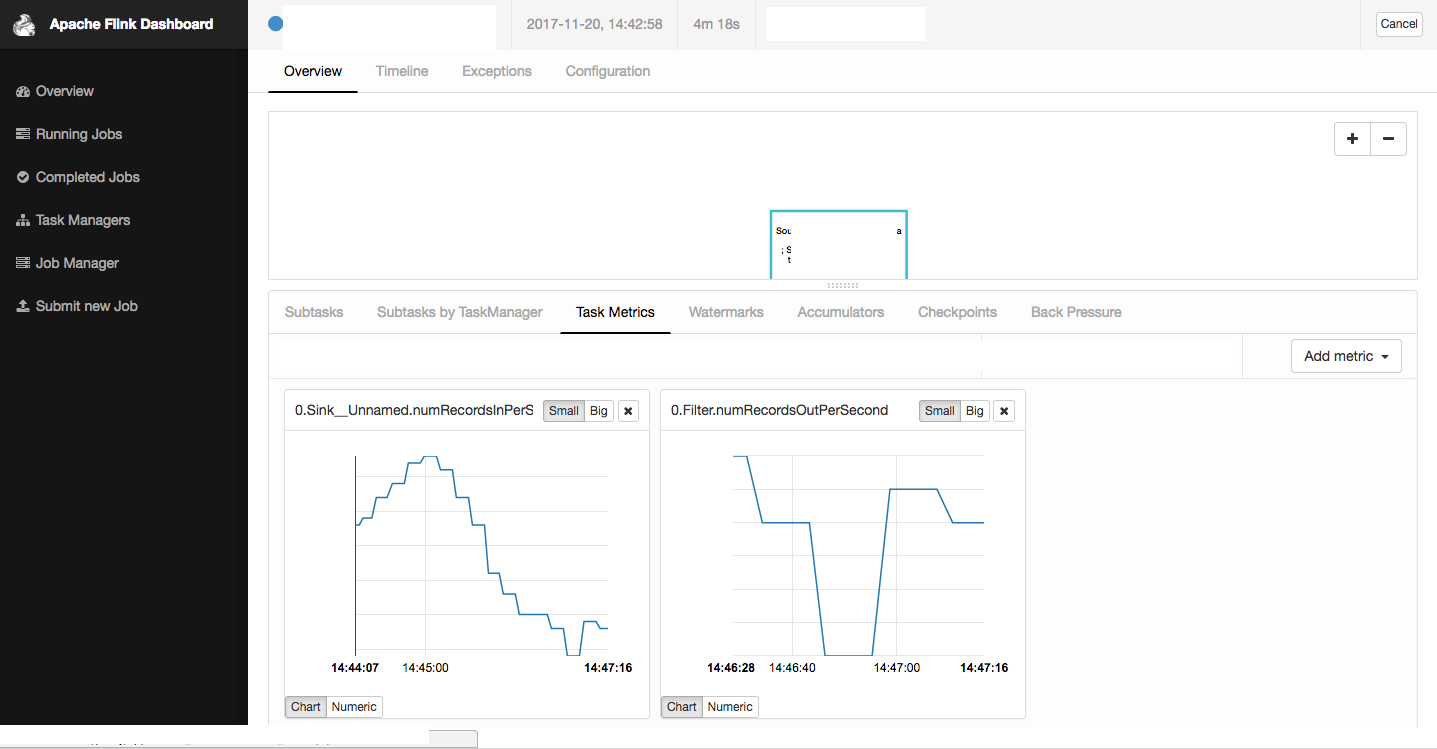
Flink Dashboard 를 이용해보신 분들이라면 Flink 의 매력에 푹 빠지실 겁니다.
기본적인 모니터링 기능 제공 ( Job 의 상태, Task manager 별 Latency, Source/Sink Msg 수 등 ) 뿐 아니라 Log finder 기능 ( 진짜 이게 판타스틱! ), Job Submit/Cancel 등의 기능을 제공하고 있습니다.
ㅁ Log finder
위 사진에서 보안상… :) 어쩔수 없이 삭제했만 Task Manager 를 보시면 내 job 이 실행되고 있는 Task Manager ( = Spark 의 executor 와 비슷한 개념 )
들이 보입니다. Error 가 난 Task Manager 의 Hostname( or IP ) 도 뜨고 해당 Task Manager 의 Error 로그만, 전체로그만 따로 볼수 있습니다.
운영해 보신 분들이라면 로그를 잘 적재하고, 에러가 났을 때 쉽게 에러난 부분을 찾는게 얼마나 귀찮고 짜증나는지 알 것입니다. 이거 때문에 로그 설정을 잘해야 하기도 하고, 더 나아가서는 yarn 설정 자체를 건드려줘야 하는 경우가 있을 수 있죠. 근데 Flink 는 정말정말 기본 설정이 잘 되어 있습니다. 에러가 나면 에러가 난 Task Manager 의 로그만 따로 볼 수 있도록 한점. 또 Error Stack Trace 로그만 따로 볼 수 있는 기능을 Dashboard 에서 제공해 줍니다.
ㅁ Job Start & Cancel
역시 Dashboard에서 Job 을 Start 및 Stop 을 할수 있습니다. ( 몇가지 제약 조건이 있지만요 ^^; )
ㅁ Docs….. good…
Flink 는 정말 책을 읽는 다는 느낌이 들정도로 책이 자세합니다. 예를들어
Best Practice : Flink’s Best practice
운영을 할때 이런부분을 조절해서 써라… 하는 가이드가 있습니다.
그리고 왜 그러지 싶을 정도로 책들도 Flink 책들이 자세히 써 있습니다 ^^; (물론 제 개인적인 생각 ㅋㅋ )
(링크 : OREILLY Flink books )
마지막으로…
아래는 개인적인 의견을 한번 정리해보았습니다.
ㅁ 꼭 Resource manager 가 필요하다고는 생각 안합니다.
ㅁ 스트림즈만 하고 싶다면 Flink 를!

아래 영상을 보시면 Spark 은 Streaming Join 이 불가능하지만,
Flink 는 가능하다는 설명이 나옵니다. 그만큼 스트리밍 관련되서 많이 발전된건 아직 Flink 인것 같네요. 그리고 Spark 의 Micro batch 또한 Streaming 에서는 그 한계를 보이는것 같습니다.
( 링크 : Predictive Maintenance with Apache Flink - Dongwon Kim (SK telecom) )
Data Strata 2017 in Singapore 에 다녀왔습니다. ( 생생한 후기는 다음 글에서 적을게요 ㅎㅎ ) 거기서 있던 Top five mistakes when writing streaming applications 발표에서 발표자가 Flink 를 제외한 다른 Streaming System 돌려까기를 시전했습니다. 보통 Streaming 시스템에서는 이런 부분을 이렇게 처리해야 해요… 아 근데 Flink 는 그냥 됩니다. 뭐 이런 말투로 말이죠… ㅎㅎ 국내에선 Flink 가 많이 인기가 없어보이지만 해외에선 사뭇 다른 느낌을 많이 받았습니다.
ㅁ 수초의 Latency 도 견딜수 없다면 Kafka or Flink 를!
위에서 설명했듯이 Spark 의 Micro Batch 구조상 1초 아래로 Duration 을 내리는게 거의 불가능하다 보시면 됩니다 :)
ㅁ 쫌 더 세분화된 Windowed 기능을 이용하고 싶다면 Flink, Kafka 를!
- Session Windowed 기능은 Flink, Kafka 만
- Count Windowed 기능은 Flink 만
ㅁ 딥러닝과의 Integration 을 고민한다면… 현재시점에선 Spark 일듯!
Spark Summit 2017 의 키노트 영상을 보면 Streaming 과 Deep Leaning 가장 핫한 키워드로 제시합니다. 이미 이 두 영역을 결합하려는 시도가 Spark 진형에서는 많이 일어나고 있습니다. 그 예로 Tensorflowonspark 가 현재로썬 그나마 커밋수가 올라가는 중입니다… ㅎㅎ( 그나마 입니다… ㅠㅠ ) 물론 Flink 도 지원을 하려는 시도가 있긴 합니다. Flinkonspark 라고 Flink Forward 2017 에서 발표 된 프로젝트인데.. 이유는 모르겠지만 커밋이 멈췄습니다 ㅠㅠ ( Flink 힘내… )
ㅁ Flink… 빨리 1.4 가 stable 로 올라가길… ㅠㅠ
회사에 Flink 를 적용하려 했을 때 제일 당황스러웠던 문제가 1.3.2 Stable 버전이 회사 Yarn Cluster 에서 작동하지 않는 문제였습니다. 이유는 Job 을 컨트롤 할때 consitent hostname normalization 이 안된 탓인데요. 자세한 내용은 Akka hostnames are not normalised consistently 이곳을 참고해 주세요 :)
TFServing(Tensorflow serving) 과의 연동 등에서도 아직 1.3.2 는 문제가 있다고 합니다. 여튼 1.4 branch 에는 해당 내용도 같이 수정되어
merge 되었다고 하니 한번 기대해 보겠습니다.
ㅁ 난 하나밖에 못하오…. 라고 한다면 Spark 를?!
오늘은 Streaming Service 의 글을 다뤄서 Kafka 와 Flink 도 같이 다뤘습니다. 그리고 실제 업계에서 Streaming 만을 위한다면 그래도 Flink 가… 라는 말이 많이 있습니다. Project Scafolding 부터 Source, sink 의 개념을 이용한 connector 는 그 코드 또한 너무 간결하여 아름다워 보이기까지 하니까요. 하지만 Spark 의 강점은 위에만 있는 것이 아닙니다. 수많은 Commiter, Star 수. Databricks 의 지원, 분석/ML/Batch/Python 호환, Deep Learning Integration 등 많은 영역의 범주를 포함하려 하는 방향성이 Spark 의 인기를 만든 것이라 생각합니다. 본인의 업무가 Streaming 만 하는게 아니라면 좀더 Full Framework 에 가까운 Spark 이 낫지 않을까 생각합니다.