.jpeg)
Spark ALS Tuning By Intel ...
Overview
오늘 다룰 내용은 Spark 에서 추천 서비스를 위해 제공하는 ALS 알고리즘에서 있었던 문제들과 이를 어떻게 튜닝했고, 얼마나 성능이 좋아졌는지에 대해 발표한 내용을 공유하는 자리입니다. ( Intel 이 튜닝한 내용을 참조했습니다. )
사실 이 부분에 대해서 공부하고, 발표를 준비 하면서 많이 든 생각은 “스파크 정도 되는 오픈소스를 하시는 분들도 이런 실수를 하는구나…” 를 느끼면서 대용량 데이터를 이용하여 추천 서비스를 하는게 얼마나 어려운지와 “과연 AI 에서는 알고리즘이 다 일까? 빅데이터를 넘어서 AI 의 시대로 가고 있는 이 상황에서 엔지니어들이 positioning, contribute 할 수 있는 부분은 어떤 부분이 있을까?”에 대한 어느정도 방향 제시가 되었다 생각하여 정말 기쁩니다.
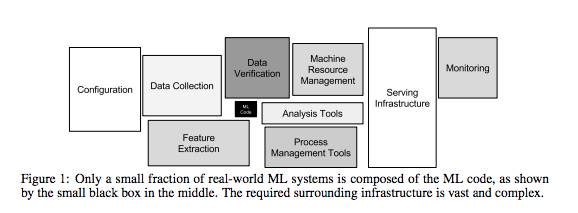
링크 : Google’s Hidden Technical Debt in Machine Learning Systems
구글에서 2015년에 발표한 문서입니다. 대략적인 내용은 “Machine Learning 은 우리에게 판타스틱한 기능을 제공함은 분명하지만 대충대충 빠르게 만든 ML 서비스는 매우 비싸고 힘든 유지비용이 들것이다.” 라는 것입니다.
으잉?? 왠 갑자기 ALS 알고리즘 튜닝 얘기한다 하시고 이런 걸 설명하죠?? +_+??
Intel 에서 Spark 의 ALS 알고리즘을 튜닝한게, 과연 단순 알고리즘의 문제였을까요?
오늘의 얘기는 제가 보여드린 이 그림을 마음속 한켠에 간직하고 보시면 어떨까 싶습니다 :)
Spark Recommendation System
당연히 Spark 문서에도 잘 나와있구요 :)
링크 : Spark Collaborative Filtering
알고리즘에 대해서는 많은 분들이 잘 설명해주셨습니다. ㅎㅎ
특히 아래 slide share 가 깔끔하게 잘 설명 되어 있더라구요.
링크 : ALS WS에 대한 이해 자료
ALS summary
사실 오늘 얘기는 ALS 알고리즘에 대해 다루진 않을 겁니다. 설명이 잘되어 있는 블로그도 많고 오래된(?) 알고리즘 이라 저보다 더 많은 고수들이 많으실 것이기에… +_+… ( 절대 귀찮아서 아닙니다… ㅋㅋ )
Spark ALS example 코드는 spark github 에서 보실수 있습니다 ㅎㅎ
링크 : Spark ALS Example
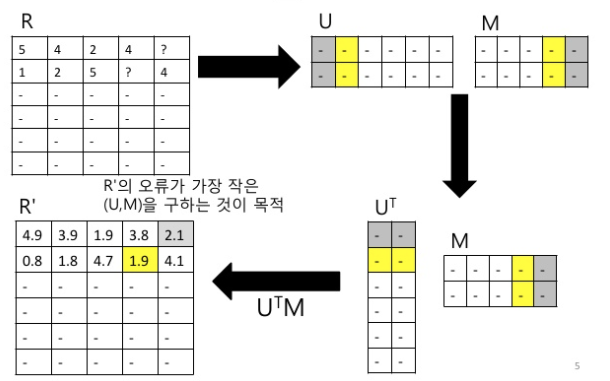
CF 의 한 종류인 MF 를 하는 방법중 하나 인데요. User to Item 의 Score 을 ( 이때 스코어가 explicit 일수도 implicit 일수도 있습니다. ) 표현되어진 Matrix 가 있다면 이를 적당한 Rank 를 가진 User Latent Feature Matrix 와 Item Latent Feature Matrix 로 분해하는 것입니다. 보통 Rank 를 구하는 방법도 여러가지 있지만 Spark 의 ALS 알고리즘 에서는 이를 하나의 하이퍼 파리미터로 생각하고 User 가 Rank 값을 적절하게 정해주도록 되어 있습니다. ( Convex Relaxation 을 통해 최적의 Rank 구하는 방법도 있는거로 압니다. 😃 )

이때 Iteration 한번에 User Vector 를 고정시킨 후 Item Vector 를 변경하고, Item Vector 를 고정시키고 User Vector 값을 변경하고 … 이렇게 여러번 하다보면 상당히 그럴싸한(?) User Vector 와 Item Vector 가 나옵니다~~ 이런 얘기 입니다. ㅎㅎ
사실 앞 수식이 제일 critical 하고, 뒤에는 Overfitting 을 방지하기 위한 Tikhonov regularization 입니다. 또 Feature 의 성향에 따라 negative 한 값을 줘도 되는지 아니면 all positive 한 값으로 Feature 를 구해야 하는 지 등 변형해서 쓸 수 있습니다. ( Spark 에서는 nonnegative 는 false 가 default 입니다 ㅎㅎ )
참고로 Nonnegative 와 negative 는 Latent Feature 를 Optimization 하는 방식이 다릅니다. 앞에껀 NNLS 를 사용하고 뒤에껀 Cholskey decomposition 을 사용합니다. 둘마다 특징이 있으니 이점 참고하세요 :)
Problem
ㅁ GC Problem and OOM frequently in recommendForAll method
링크 : SPARK-20446
내용은 간단합니다. User Vector * Item Vector 계산 시에 Top Item 을 뽑아오는 로직에서 계산된 모든 결과를 저장하지 않고 가져올 Top N 의 갯수만 저장하겠다는 것입니다. 이전에는 User 별로 Item Prediction Score 를 전부 저장하고 그 걸 sorting 해서 top N 을 가져오는 것이였는데, Item 갯수가 많을 경우 당연히 시스템이 뻗겠죠 ^^;
ㅁ mllib/src/main/scala/org/apache/spark/mllib/recommendation/MatrixFactorizationModel.scala
변경전
...
val srcBlocks = blockify(rank, srcFeatures)
val dstBlocks = blockify(rank, dstFeatures)
val ratings = srcBlocks.cartesian(dstBlocks).flatMap {
case ((srcIds, srcFactors), (dstIds, dstFactors)) =>
val m = srcIds.length
val n = dstIds.length
val ratings = srcFactors.transpose.multiply(dstFactors)
val output = new Array[(Int, (Int, Double))](m * n)
var k = 0
ratings.foreachActive { (i, j, r) =>
output(k) = (srcIds(i), (dstIds(j), r))
k += 1
...
변경후
...
val srcBlocks = blockify(srcFeatures)
val dstBlocks = blockify(dstFeatures)
val ratings = srcBlocks.cartesian(dstBlocks).flatMap { case (srcIter, dstIter) =>
val m = srcIter.size
val n = math.min(dstIter.size, num)
val output = new Array[(Int, (Int, Double))](m * n)
var j = 0
val pq = new BoundedPriorityQueue[(Int, Double)](n)(Ordering.by(_._2))
srcIter.foreach { case (srcId, srcFactor) =>
dstIter.foreach { case (dstId, dstFactor) =>
...
Spark 을 튜닝할때 가장 키포인트가 뭘까요?
본인이 만든 프로그램이 겁나 느려져서 빡세게 고생 해보신 분들(?) 이라면 아실겁니다. 바로 shuffle 을 줄이고, memory 사용을 줄여라 입니다. ( 아! 너무 당연한 얘기인가요…? ㅋㅋ )
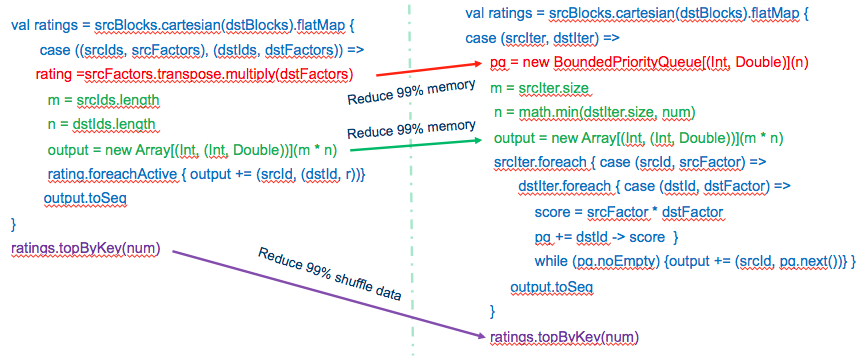
혹시 위에 그림을 보기 전에 source change 결과만 보시고 이 모든 결과를 예상하셨다면 당신은 Spark 를 꽤(?) 잘하는 것입니다 :) ㅎㅎ top n 을 뽑는건 단순히 memory 에만 영향을 주는 것이 아닌 shuffle 의 양을 줄여주기 때문에 엄청나게 빠른 결과를 줄것 같아! 라는 예상을 할수 있을 겁니다.


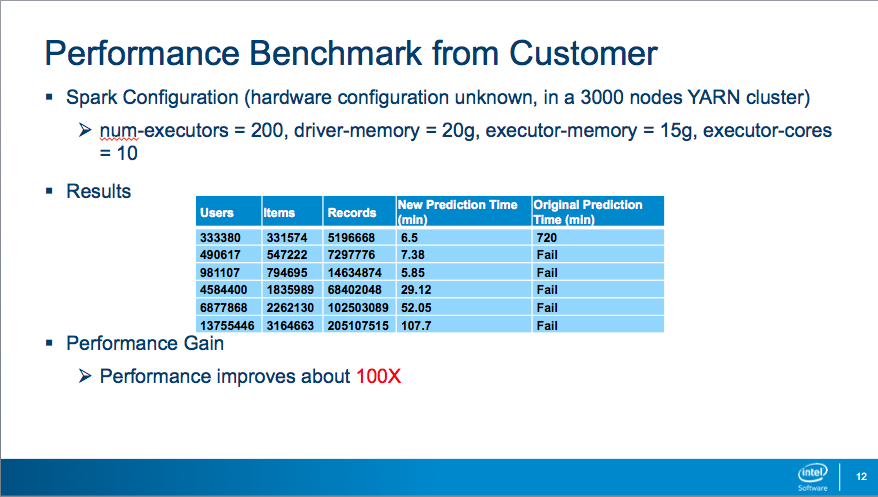
위에는 밴치마크 결과 입니다. 참고 하세요. ㅎㅎ
ㅁ Block-Size is static
링크 : SPARK-20443
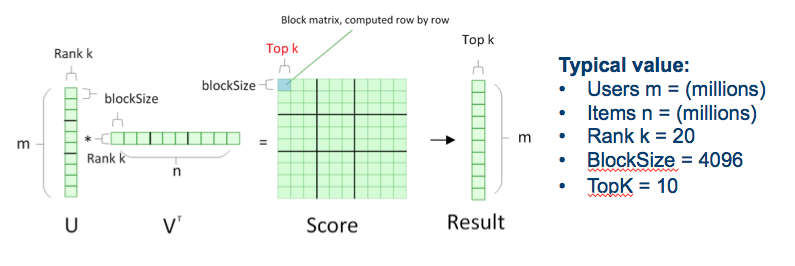
Spark 에서는 Matrix 계산을 할때 cell(?) 단위로 하지 않고 Block Manager 를 거쳐 계산됩니다. 즉, Spark 에서 Data shuffle 의 기준을 이 Block Matrix 로 잡게 되죠. 다만, recommendForAll method 에서 기본적인 block size 가 4096으로 고정되어 있는게 문제였는데요.
mllib/src/main/scala/org/apache/spark/mllib/recommendation/MatrixFactorizationModel.scala
변경전
private def blockify(
rank: Int,
features: RDD[(Int, Array[Double])]): RDD[(Array[Int], DenseMatrix)] = {
val blockSize = 4096 // TODO: tune the block size
val blockStorage = rank * blockSize
변경후
private def blockify(
features: RDD[(Int, Array[Double])],
blockSize: Int = 4096): RDD[Seq[(Int, Array[Double])]] = {
user, item matrix 를 inner product 할때 block 의 size 를 조절할 수 없도록 고정시켜놨습니다. executor 가 몇개인지 한 executor, core 당 할당 받을 수 있는 메모리가 몇인지 cpu 의 register, cache, memory 에 따라 computing 시간은 천차 만별일 것입니다.
1차
BlockSize(recommendationForAll time)
128(124s), 256(160s), 512(184s), 1024(244s), 2048(332s), 4096(488s), 8192(OOM)
The Test Environment:
3 workers: each work 10 core, each work 30G memory, each work 1 executor.
The Data: User 480,000, and Item 17,000
2차
3 workers: each work 40 core, each worker 180G memory, each worker 1 executor.
The Data: user 3,290,000, and item 208,000
The results are:
blockSize rank=10 rank = 100
128 67.32min 127.66min
256 46.68min 87.67min
512 35.66min 63.46min
1024 28.49min 41.61min
2048 22.83min 34.76min
4096 22.39min 54.43min
8192 23.35min 71.09min
어떨 때는 block size 를 크게 하면 좋고, 어떨때는 작게 하면 좋고, 어떨때는 적당히 큰값으로 하는게 좋습니다. 사실 이건 저도 고민을 해봤는데 테스트를 통해서 밖에 알 수 없을거 같네요 ^^; 위에서 살짝 언급 드렸다 싶이 computing 이라는게 단순하게 cpu, RAM 을 늘린다고 좋아지는게 아닙니다. cpu 와 RAM 중간에서 memory 가 왔다갔다 하는 것도 고려를 해야지요. ( 혹시 이런거 계산해서 block size 정할 수 있는 방법 아시는 재야의 고수님들 있으면 쪽지 좀 주세용 ㅎㅎ)
ㅁ Optimize the Cartesian RDD
링크 : SPARK-20638
core/src/main/scala/org/apache/spark/rdd/CartesianRDD.scala
변경전
override def compute(split: Partition, context: TaskContext): Iterator[(T, U)] = {
val currSplit = split.asInstanceOf[CartesianPartition]
for (x <- rdd1.iterator(currSplit.s1, context);
y <- rdd2.iterator(currSplit.s2, context)) yield (x, y)
변경후
override def compute(split: Partition, context: TaskContext): Iterator[(T, U)] = {
...
val resultIter =
for (x <- rdd1.iterator(currSplit.s1, context);
y <- getOrElseCache(rdd2, currSplit.s2, context, StorageLevel.MEMORY_AND_DISK))
yield (x, y)
...
Cartesian RDD ( Spark core ) 에 문제가 쫌 있습니다. Large size 한 RDD 를 cartesian join 할 경우 곱해져야 할 RDD 가 중복되어서 계속 전송하게 됩니다. 사실 한번 전송 받은 RDD ( 여기서는 block 이라고 할까요? matrix 연산을 block 단위로 하고 있으니까요 ㅎㅎ ). block 은 전송할 필요가 없습니다. 그래서 RDD 의 저장 방식을 변경하고 local ( excecutor ) 에 저장하고 있다고 없을때만 전송받고 있을 땐 memory or disk 에서 꺼내서 계산합니다.
링크 : 소스 참조 (https://github.com/apache/spark/pull/17936/files)
아.. DF 를 쓰는 spark 2.x 에서는 내부적으로 cross join 이 구현 되어 잇어 key optimazation 을 탑니다. 크게 성능 저하가 없습니다. 이미 테스트도 완료했으니 2.x 를 쓰시는 분들은 그냥 쓰셔도 괜찮아요 ^^ (참고로 이 부분은 spark core 부분이라 그런지 아직 fixed 되지 않은 부분입니다.)
ㅁ The BKM (best known methods) of using native BLAS to improvement ML/MLLIB performance
링크 : SPARK-21305
추가
...
+# Options for native BLAS, like Intel MKL, OpenBLAS, and so on.
+# You might get better performance to enable these options if using native BLAS (see SPARK-21305).
+# - MKL_NUM_THREADS=1 Disable multi-threading of Intel MKL
+# - OPENBLAS_NUM_THREADS=1 Disable multi-threading of OpenBLAS
...
Spark ML, MLLIB 에서 사용하는 BLAS 라는 library 에서 multi threading 을 쓰는 설정이 이상하다고 하네요. 위와 같이 수정하고 쓰면 좀 더 나은 성능을 볼 수 있다고 합니다. (아, 물론 MKL, BLAS 를 잘 쓰시려면 빌드단계부터 운영 환경과 맞춰 잘 해줘야 합니다. )
Result
음… 일단은 위에 수정된 내용들이 전부 Master Branch 에 적용된 상태는 아닙니다. 결국 RDD 기반의 mllib 을 쓸거면 반영이 안된 부분은 본인이 수정해서 쓰던지… DF기반의 ml 을 써도 마찬가지 입니다. cartesianRDD 만 crossjoin 으로 대체 가능한 거지 나머지 부분은 수정해서 써야 한다는 것이지요. 하지만 작은 사이즈는 문제가 없습니다. ^^ 그래도 역시 Spark 이니까요 ㅎㅎ 이것저것 다 귀찮으시면… 2.3rc-1 으로 해보셔도 괜찮을 듯 싶습니다 ㅎㅎ ( 해보진 않았습니다. ) 2.3 이 latest stable 로 빨리 올라오길 기원합니다. ( 이 글의 초안을 쓴지도 어엿 2~3달이 지났네요 ^^; ㅎㅎ 이제는 2.3 이 latest stable 입니다. )
부흥하라! 데이터 엔지니어여
자! 이제 다시 돌아와서 ㅎㅎ
사실 최근에 굉장히 고민이 많았습니다. 최근에 워낙 분석이나 ML/DL이 각광받다보니 서버나 엔지니어링 쪽 공부보단 분석이나 모델링 공부를 많이 해야겠다고 많이 느꼈습니다. 하지만 하면서 고민되었던게 내 커리어는 엔지니어로 계속 가고 싶은데 이렇게 공부하고 일을 하면서 과연 내가 2~3년 뒤에는 내 커리어는 뭐가 되어 있을까? 라는 고민을 많이 하게 되었죠.
근데 이 발표를 준비하면서 많이 느꼈습니다. 그렇게 common 하고 쉽다고 느끼던 ALS 알고리즘 조차 대용량으로 가면 하기 어렵다는 걸요. 날고 긴다는 Spark 커미터들 조차도 이 버그를 수정하는데 버전 2.3까지 끌었습니다. 예전에 @권혁진 님께서 스사모에서 발표해주실때 Spark 에 ML 관련된 커미터가 다른 component에 비해 많이 부족하다고 하셨습니다. 그 이유는 Modeling 과 Engineer 를 둘다 할 줄 아는 개발자가 많이 없기 때문이라고 하셨죠.
추천 서비스를 해보면서 느낀 점은 저희가 만든 알고리즘을 서비스에 올려서 돌려보면 “기가 막힌 모델”이 이길 때도 있지만 “빠른 training/inference 되는 모델”이 이길때도 있습니다. 그때 그때 다르겠죠. 그냥 간단히 생각해보면 번역이나 이미지 인식은 정교하게 잘 짜여진 모델이 이길겁니다. 근데 시시각각 바뀌는 상황에선 오히려 새로운 데이터로 계속 모델을 바꿔쳐 주는게 이길 수도 있겠죠.
데이터 엔지니어, 분석가, 모델링. 이를 잘 융합하는 기업이 이길거란 생각이 듭니다. ( 너무 당연한 건가요? ^^; ㅎㅎ )
이제는 엔지니어도 같이 이러한 모델이 좋을까? 학습하려면 어떻게 networking 해야 할까? 분산 training 은 가능할까? 모델은 어떻게 serving & deploy 하지? 그때 무중단을 해야할까? 할수 있을까? F/W 은 뭘 선택하지? 등등 ML 서비스를 위해 시스템을 어떻게 설계할지 함께 고민해봐야 하는 시대가 아닌가 생각합니다. :)